PEG Explorer
Part of Mouse version 2.3
In its external appearance, PEG is very like an EBNF grammar. But, the limited backtracking may result in some strings conforming to EBNF being rejected by PEG. If you do not want to exploit the quirks of PEG, you would most likely see your grammar as EBNF and expect the PEG parser to behave accordingly. Indeed, for some grammars the limited backtracking finds everything that would be found by full backtracking. We say that such grammar is "PEG-complete". A PEG parser for PEG-complete EBNF grammar accepts exactly the language defined by that EBNF.
The limited backtracking of PEG
applies to expressions of the form e1/e2.
It means that once e1 succeeded,
there is no attempt to try e2 in the case of a later failure.
In EBNF, e1/e2 defines the union of languages
of e1 and e2.
But, limited backtracking may exclude the language of e2
or part of it.
One can easily see that limited backtracking will not exclude e2
if A = e1/e2
satisfies this condition:
(C)
No string defined by e1
is a prefix of any string defined by e2 Tail(A)
where Tail(A) is
the set of all strings that can follow A
in a string conforming to the grammar.
A special case of (C) is that first letters of strings
defined by e1
are distinct from first letters of strings defined by e2 Tail(A).
This is known as the LL(1) condition,
and is easily checked.
Many expressions that do not satisfy LL(1) still satisfy (C),
but there is no general way to check this.
However, a large number of cases can be checked by inspection.
PEG Explorer checks the LL(1) condition for all expressions e1/e2 in the given grammar
and lets you inspect those that fail the test.
Rather than working with single letters, PEG uses "terminals"
that may be strings of letters of sets of letters.
The LL(1) condition is thus understood so that e1 and e2
begin with terminals that are "disjoint".
The expressions A = e?, A = e*
and A = e+
are abbreviations for, respectively,
A = e/ε, A = eA/ε
and A = ee*,
where ε is the empty word.
For these expressions (C) becomes:
(C')
No string defined by e
is a prefix of any string defined by Tail(A),
and the LL(1) condition is that e and Tail(A)
begin with "disjoint" terminals.
In the following, the Explorer is introduced by applying it to two grammars supplied with Mouse as examples.
Explore Examples
Example 4
Using command prompt, go to the directory Mouse\examples\Example4 and enter the command:
java mouse.ExplorePEG -G myGrammar.txtThe command should open a window like this:

You see there all Rules of the grammar.
By clicking the "All" button you can see all subexpressions,
with names indicating their positions within a Rule:

By selecting a line and clicking the "Find" button you see only the expressions using the selected expression. You can use the "Rules", "All", and "Find" buttons to switch between these views.
By clicking the "Non-LL1" button, you can see all choice expressions that do not satisfy LL(1). The result is here as follows:

It tells you that the choice in "Number" does not satisfy LL(1). Which is rather obvious since both alternatives may start with "Digits". To explore it, click on the line. Or select the line and click the "Show" button. The result is a new window that looks like this:

You see here again the LL(1) conflict that you are going to explore,
and the reason for the conflict:
both alternatives define strings that may start with [0-9].
The expressions above and below "========"
are, respectively, e1 and e2 Tail(A) in
the condition (C) that you want to check.
To see if they satisfy (C), you will transform the expressions.
You may start by clicking on "Digits?". (You may instead select "Digits?" and click the "Expand" button.) The result is as follows:

You replaced "Digits?" by its defiition, that is, "Digits / ε". The top expression is now
(Digits "." Digits Space) / ("." Digits Space),
with two alternatives represented as two lines.
It is equivalent to the original e1.
Clearly, the second line can not define a prefix of the bottom expression, so this alternative can be ignored in further exploration. By clicking the "Filter" button, you remove alternatives with first terminals disjoint with first terminals of all strings represented by expressions on the other side of "========". The result is as follows:
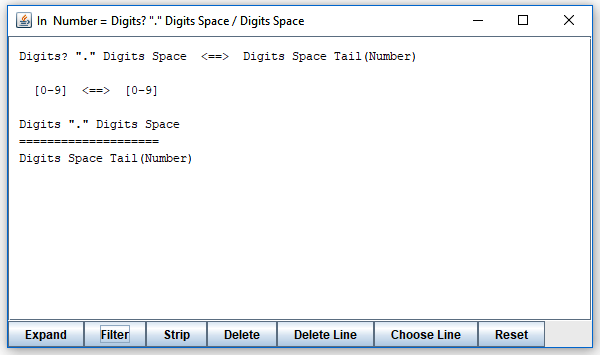
To see if any string defined by the top expression can be a prefix any string defined by the bottom expression, you need to see the strings represented by "Tail(Number)". These are the strings that can follow "Number" in an input conforming to the grammar. You find them by clicking on "Tail(Number)", which produces this result:

Here "Tail(Number)" has been expanded to "(AddOp Number)* !_".
You can immediately see that "Digits" can only be followed here by a plus or minus or end of text, possibly preceded by white space. As "Digits" in the top expression are always followed by a dot, none of these strings can be a prefix of a string defined by bottom expression.
To become better convinced, you may click the "Strip" button. It eliminates "Digits" from furhter consideration:

Clicking now the "Filter" button produces this:

showing that the top and bottom expressions to the right of "--" had mutually disjoint first terminals. You have thus verified that the expression being explored satisfies (C), and its limited backtracking is efficient. As it was the only one left after the LL(1) check, limited backtracking is efficient for all expressions in the grammar. The grammar defines thus the same language as its EBNF interpretation.
Example 5
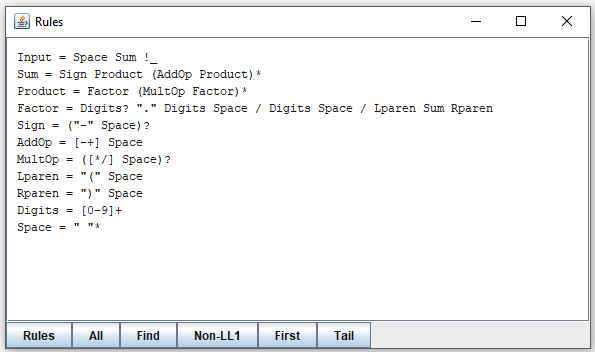
Using command prompt, go to the directory Mouse\examples\Example5 and enter the command:
java mouse.ExplorePEG -G myGrammar.txtThe command should open this window:
A click on "Non-LL1" produces this:
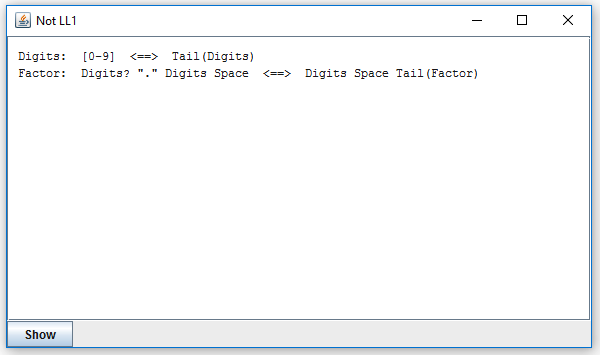
A click on the first line opens this window:

It tells you that the expression "Digits", defined as [0-9]+, does not satisfy LL(1). The condition (C') is in this case that [0-9] must not be a prefix of any string in Tail(Digits), which is stated by the first line in the window. The second line shows that, unfortunately, Tail(Digits) contains a string starting with [0-9]. It means that "Digits" does not satisfy (C'). The parsing expression [0-9]+ will gobble up any [0-9] from the following Tail(Digits) and will never backtrack to try gobbling less. You may want to find out where does this happen. For this purpose you have to take a closer look at "Tail(Digits)".
A click on "Tail(Digits)" has this effect:

A click on "Filter" followed by a click on "Tail(Factor)" produces this:

Finally, a click on "(MultOp Factor)*" gives this result:

The expressions under "========" represent the possible strings belonging to "Tail(Digits)". You know that both "Space" and "MultOp" may both represent empty strings. (You may well click on them to check). You also know that "Factor" may start with "Digits", and thus with [0-9]. (Again, you may use some clicks to check that.)
Here is the culprit: the "Digits" in question must be those appearing at the end of a "Factor". Our inspection shows that they may be immediately followed by "Digits" starting another "Factor". The EBNF form of the grammar is thus ambiguous: with empty string as multiplication operator, "23" may be interpreted as either the number "23" or product "2 times 3". PEG will choose one of these alternatives, namely the number "23" and not backtrack to try the other one. As this happens to be exactly how a human reader interprets "23", you may accept this behavior.
You can now close the window, which brings you back the the "Not LL1" window, and explore the other case shown there. It boils down the the same problem: the ambiguity when a multiplication operator between two Factors is the empty string.
More tools
The two examples above presented most of the functions used to explore an LL(1) conflict. Here comes the rest.
Select single terminal conflict
Sometimes an LL(1) violation may involve sevaral pairs of conflicting terminals, like in this case:
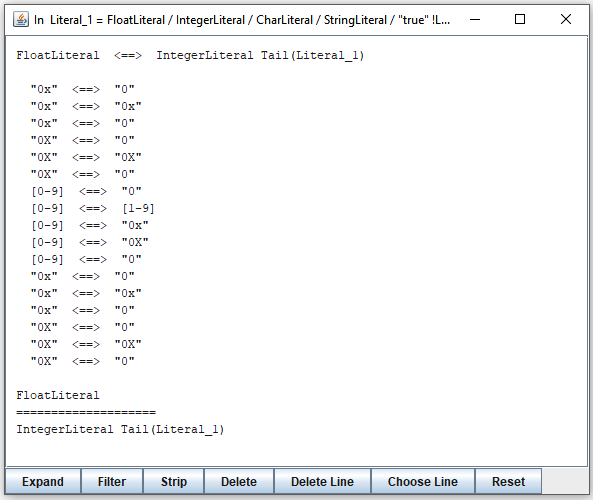
It comes from one of the sample Java grammars. You can see here that, for example, a string in "FloatLiteral" may start with [0-9] which the parser may confuse with "0x" that starts a string in "IntegerLiteral". You may decide to examine only the strings starting with exactly these terminals. To do this, you click on the line [0-9] <==> "0x". It changes the window as follows:
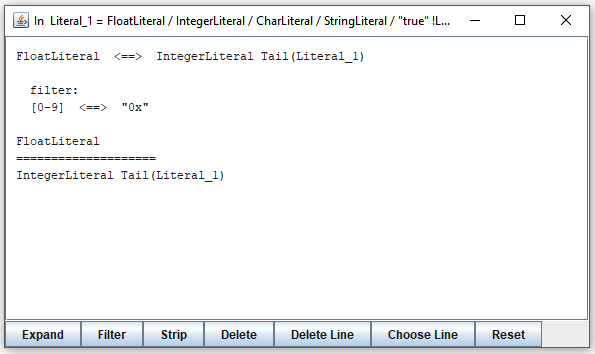
From this moment on, expressions not containing strings starting with selected terminals will be filtered out. For example, two steps in expanding "FloatLiteral" and "IntegerLiteral" will look like this:
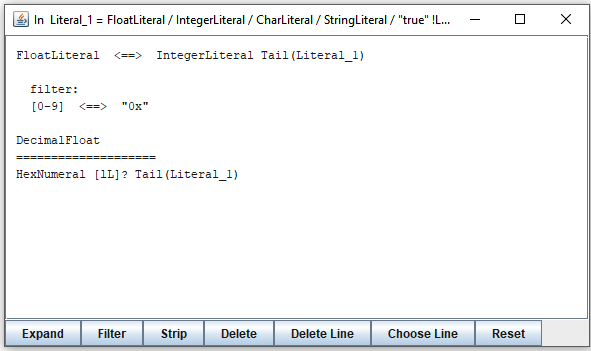
You see that the only alternatives left are those starting with [0-9]
respectively "0x".
(Of course, this filtering stops as soon as you use the "Strip" function.)
Ignore part of expression
Sometimes you want to ignore a specific subexpression such as "Space". By selecting it with the mouse and clicking the "Delete" button you remove it from the expression.
You may also remove a line by selecting any item within it and clicking "Delete Line". By clicking "Choose Line" you remove all lines except the selected one.
Return to square one
By clicking the "Reset" button you return to the original presentation of the conflict.
(An "undo" function reversing a single operation may be implemented later on.)
Handle predicates
An automatic checking of the LL(1) condition in presence of predicates is difficult. Therefore the Explorer approximates the condition by assuming that all predicates succeed. This results in many false alarms, and you have to decide by inspection whether the alarm is false or not. The following is a typical example taken again from Java sample grammar:

You decide to have a closer look at the first pair of terminals and after a couple of "Expand" operations you obtain this:

A final click on "Identifier" reveals this:

In the computation of LL(1), "!Keyword" was assumed to succeed, that is, to represent empty string; thus, the bottom expression was allowed to define strings starting with "Letter", which may be any of [a-z], for example, b. This also happens to be the first letter in "byte", so we have an LL(1) conflict.
This version of Explorer does not allow you to expand the contents of the predicate, but you can find in the grammar that "byte" followed by !LetterOrDigit is a special case of "Keyword". Thus, "!Keyword" fails on that string, so it can not be a prefix of anything defined by the bottom expression. The alarm was false and the choice satisfies (C).
Left recursion
For a grammar containing left recursion, Mouse constructs behind the scenes the "dual" grammar, as explained here. The dual grammar is not left-recursive; Mouse treats it as PEG and generates a PEG parser for it. The dual grammar defines the same language as the original one. So, if the dual grammar is PEG-complete, the parser correctly accepts the language of the original grammar. You use Explorer to check if the dual grammar is PEG-complete.
To try it, go to the directory Mouse\examples\Example4R that contains a left-recursive version of Example4. To see the grammar, enter the command:
java mouse.TestPEG -G myGrammar.txt -DLTo explore the dual grammar, enter the command
java mouse.ExplorePEG -G myGrammar.txtThe command should open this window:

You can see there, at the end, three expresions that replace left-recursive expressions of the original grammar. They are "Sum", "$Sum", and "$Sum_0".
Explore expressions
First
You can explore individual expressions, starting with the window "Rules", "All", or "Find". In each of them you can select an expression with the mouse.

Suppose you have selected "Factor". By clicking on the "First" button, you open a new window that shows the expressions that "Factor" may call to consume the first portion of its input:
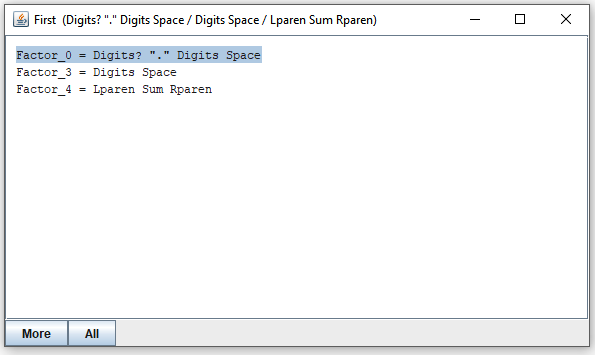
By clicking on any of them (or selecting and clicking "More") you see expressions that the selected expression may call first:
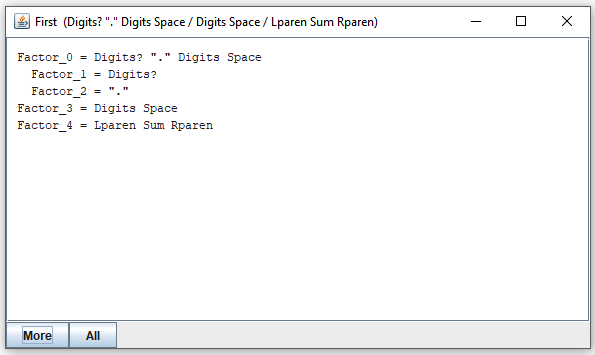
Here you clicked on "Factor_0", and you can see that it can may call "Digits?" or "." to consume the first portion of its input. Proceeding in this way, you can see all expressions that "Factor_1" may invoke directly or indirectly to consume the first portion of its input:

By pressing "All" you see all expressions that "Factor" may invoke directly or indirectly as first:

Tail
By clicking on the "Tail" button, you display the Tail of expression selected on the "Rules", "All", or "Find" window.
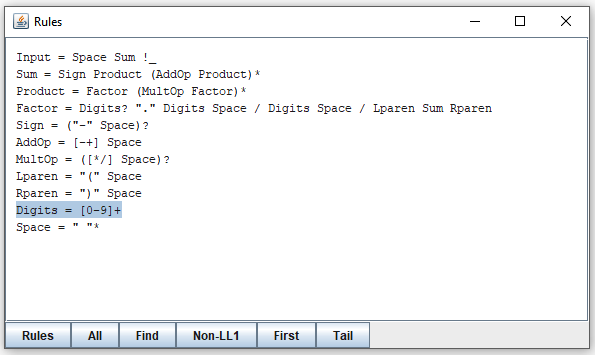
Selecting "Digits" and clicking "Tail" opens this window:

It shows what can follow after "Digits" when it is invoked in three different contexts. (As you can see, "Digits" is invoked in three different places, all from "Factor".) You can expand elements of the lines you see by clicking on them, or selecting and pressing the "Expand" button. By clicking on "Tail(Factor)" in the first line, you obtain this:

Latest change 2021-04-30